LR文法分析
- LR parser - Wikipedia, the free encyclopedia
- LR parsers are a type of
- bottom-up parsers
- that efficiently handle
- deterministic
- context-free
- > languages in
- Common variants of LR parsers
- Often mechanically generated from a formal grammar for the language by a parser generator tool.
- Very widely used for the processing of computer languages
- more than other kinds of generated parsers.
- LR is an acronym:
- L
- means that the parser reads input text in one direction without backing up
- typically from Left to right within each line, and top to bottom across the lines of the full input file.
- This is true for most parsers
- That's why linear parsing time is guaranteed.
- R
- means that the parser produces a reversed Rightmost derivation
- It does a bottom-up parse,
- not a top-down LL parse or ad-hoc parse
- LR(k)
- Often followed by a numeric qualifier
- To avoid backtracking or guessing
- The LR parser is allowed to peek ahead at "k" lookahead input symbols
- before deciding how to parse earlier symbols.
- Typically "k" is 1 and is not mentioned.
- LR parsers are deterministic
- produce a single correct parse without guesswork or backtracking, in linear time.
- Ideal for computer languages
- not suited for human languages
- which need more flexible but slower methods
- By convention
- The LR name stands for the form of parsing invented by Donald Knuth
- and excludes the earlier, less powerful precedence method
- e.g.
- Operator-precedence parser
- LR parsers can handle a larger range of languages and grammars than
- precedence parsers
- or top-down LL parsing
- This is because
- the LR parser waits until it has seen an entire instance of some grammar pattern before committing to what it has found.
- An LL parser has to decide or guess what it is seeing much sooner,
- when it has only seen the leftmost input symbol of that pattern.
- LR is also better at error reporting.
- It detects syntax errors as early in the input stream as possible.
- A * 2 + 1
- Scans and parses the input text in one forward pass over the text.
- Builds up the parse tree
- incrementally,
- bottom up,
- and left to right,
- without guessing or backtracking.
- Before there is enough input parsed for building a bigger tree or complete tree,
- Nodes built by parsed input will temporarily held in a parse stack.
- Shift and reduce actions
- Shift-reduce parsers
- is a class of efficient, table-driven bottom-up parsing methods for computer languages and other notations formally defined by a grammar.
- LR parsing is one of the shift-reduce methods.
- The outward actions of an LR parser are best understood by ignoring the arcane mathematical details of how LR parser tables are generated,
- and instead looking at the parser as just some generic shift-reduce method.
- As with other shift-reduce parsers, an LR parser works by doing some combination of Shift steps and Reduce steps.
- Shift step
- advances in the input stream by one symbol.
- That shift symbol becomes a new single-node parse tree.
- Reduce step
- applies a completed grammar rule to some of the recent parse trees,
- joining them together as one tree with a new root symbol.
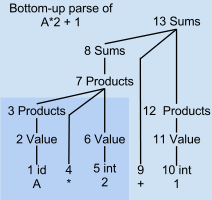
- Ex:
- A (shift)
- 1 id (reduce)
- 2 value (reduce)
- 3 Products (reduce) -> ?? not sure I get it.
- * (shift)
- 4 (reduce) -> I think 3 and 4 is misplaced, or 3 should not exist at all (??)
- 2 (shift)
- A * 2
- +
- 1
- A * 2 + 1
- LR parsers differ from other shift-reduce parsers in how they decide when to reduce
- and how to pick between rules with similar endings.
- But the final decisions and the sequence of shift or reduce steps are the same.
- Much of the LR parser's efficiency is from being deterministic.
- To avoid guessing, the LR parser often looks ahead (rightwards) at the next scanned symbol, before deciding what to do with previously scanned symbols.
- the lexical scanner works one or more symbols ahead of the parser.
- The lookahead symbols are the 'right-hand context' for the parsing decision.
- Bottom-up parse stack
- LR parser lazily waits until it has scanned and parsed all parts of some construct before committing to what the combined construct is.
- Like other shift-reduce parsers.
- The parser then acts immediately on the combination instead of waiting any further.
- Ex.
- the phase A gets reduced to Values and then to Products in steps 1-3 as soon as lookahead * is seen.
- !!!!!! answered my question very well!!
- Rather than waiting any later to organize those parts of the parse tree.
- The decisions for how to handle A are based only what the parser and scanner have already seen, without considering things that appear much later to the right.
- Reductions reorganize the most recently parsed things,
- immediately to the left of the lookahead symbol. --> Not sure I get it.
- So the list of already-parsed things acts like a stack.
- This parse stack grows rightwards.
- The base or bottom of the stack is on the left and holds the left most.
No comments:
Post a Comment