30.3.15
- A beginner's guide to Grunt · Matt Bailey
- Project Scaffolding - Grunt: The JavaScript Task Runner
- Getting started - Grunt: The JavaScript Task Runner
- javascript - grunt server can't be connected <gruntjs> - Stack Overflow
grunt.initConfig({
connect: {
target:{
options: {
port: 9001,
keepalive: true
}
}
}
});
How to Correctly Use BootstrapJS and AngularJS Together ♥ Scotch
- How to Correctly Use BootstrapJS and AngularJS Together ♥ Scotch
- Bootstrap学习 - 文章分类 - 一步两步三步向上走 - 博客园
- 这个有一些简单实用的小知识
- AngularJS Panels - simple portal widget with RESTful backend
- Simple portal system with floating panels
- Drag and Drop is supported
- JQuery UI
- To support proper binding between JQuery UI Sortable interface and AngularJS models
- Creating custom widget
- Which looks at DOM changes done by JQuery
- and map them properly back to AngularJS.
- Using JSON for the models
- $resource
- We can load any model directly from the server and save it back with one line of code.
- Bootstrap
- is used to create documentation/demo page.
- Jetty and the Yeoman Maven Plugin | patrickgrimard.com
- angularjs - How to combine Yeoman scaffolding with existing Java directory structure - Stack Overflow
- trecloux/yeoman-maven-plugin · GitHub
- npm - Install Node.js on Ubuntu 12.10 - Stack Overflow
- Getting started - Grunt: The JavaScript Task Runner
- yeoman-maven-plugin/TUTORIAL.md at master · trecloux/yeoman-maven-plugin · GitHub
- drewzboto/grunt-connect-proxy · GitHub
- Error: EACCES, open '/Users/Profile/.npm/_locks/browser-sync-ed941186c435fb34.lock' · Issue #7407 · npm/npm · GitHub
- $sudo chown -R $(whoami) $HOME/.npm
AngularJS Panels - simple portals widget with RESTful backend
- $resource('app/models/:model', {model: 'default.json'}).get();
- scope.$watch('portalModel', function() {
- scope.portalModel.$save();
- });
About AngularJS Resource
- AngularJS: Tutorial: 11 - REST and Custom Services
- ngResource
- The RESTful functionality is provided by Angular in the ngResource model.
- Which is distributed separately from the core Angular framework.
28.3.15
web.xml for J2EE 2.4 + Spring MVC
<web-app id="WebApp_ID" version="2.4" xmlns="http://java.sun.com/xml/ns/j2ee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd"> <display-name>Spring MVC</display-name> <servlet> <servlet-name>dispatcher</servlet-name> <servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class> <load-on-startup>1</load-on-startup> </servlet> <servlet-mapping> <servlet-name>dispatcher</servlet-name> <url-pattern>/rest/*</url-pattern> </servlet-mapping> <context-param> <param-name>contextConfigLocation</param-name> <param-value>/WEB-INF/dispatcher-servlet.xml</param-value> </context-param> <listener> <listener-class>org.springframework.web.context.ContextLoaderListener</listener-class> </listener> </web-app>
26.3.15
24.3.15
21.3.15
Installing Microsoft Office 2010 in Wine - Ubuntu 12.04/12.10 64-bit/32-bit | Craig Gomez
Installing Microsoft Office 2010 in Wine - Ubuntu 12.04/12.10 64-bit/32-bit | Craig Gomez
The above one doesn't work well. So I followed the following links and got the work done.
The above one doesn't work well. So I followed the following links and got the work done.
20.3.15
GIT: patch fragment without header at line
/*
* Make sure we don't find any unconnected patch fragments.
* That's a sign that we didn't find a header, and that a
* patch has become corrupted/broken up.
*/
if (!memcmp("@@ -", line, 4)) {
struct fragment dummy;
if (parse_fragment_header(line, len, &dummy) < 0)
continue;
die(_("patch fragment without header at line %d: %.*s"),
linenr, (int)len-1, line);
}
How we build microservices at Karma | Karma
I liked this post, as well as its comments. Other than Microservice architecture, people mentioned SWF (Simple Workflow), and SEDA. Need to look into it later.
15.3.15
Turning off the annoying popup in youtube videos
Some of the videos in YouTube have something keep showing up. If you find it annoying like I do, you can turn it off by:
Click on "Settings" -> Annotation -> Off
Don't understand why people even try to use this approach for advertisement in the first place at all. From my point of view, it just makes people hate the publisher of the video if the audience don't know how to turn them off.
Click on "Settings" -> Annotation -> Off
Don't understand why people even try to use this approach for advertisement in the first place at all. From my point of view, it just makes people hate the publisher of the video if the audience don't know how to turn them off.
我觉得如果大家想学习机器学习,强烈建议上www.coursera.com选andrew ng的课程。好处:(1)免费; (2)真正的名师;(3)视频讲解;(4)同步练习;(5)编程作业;(6)课程发证。呵呵,我听了Koller的概率图,收获很大。就是每个星期可能要花上10个小时完成学习,作业和编程。http://www.peileyuan.com/blogs/67 如果还不行就找个人辅导一下,或者跟谁全称学一下,有什么不能学会的呢,另外可以加一些群,和大家多聊多交流,机器学习&大数据处理交流群:299083006
14.3.15
"Collection, analytics, and reporting system, with few exceptions, scale and grow at different rates within an organization"
From "Real-time Analytics". Like this statement.
Log Formats
- National Center for Supercomputing Applications - Wikipedia, the free encyclopedia
127.0.0.1 user-identifier frank [10/Oct/2000:13:55:36 -0700] "GET /apache_pb.gif HTTP/1.0" 200 2326
- Extended Log File Format
- Extended Log Format - Wikipedia, the free encyclopedia
- Extended Log Format (ELF) is a standardized text file format, like Common Log Format (CLF), that is used by web servers when generating log files, but ELF files provide more information and flexibility.
- Extended Log File Format
From "Real-Time Analytics"
- ..., which was never intended to support the Rich Data Payloads (and does so poorly).
9.3.15
6.3.15
LR文法分析
- LR parser - Wikipedia, the free encyclopedia
- LR parsers are a type of
- bottom-up parsers
- that efficiently handle
- deterministic
- context-free
- > languages in
- guaranteed linear time.
- Common variants of LR parsers
- LALR
- SLR
- Often mechanically generated from a formal grammar for the language by a parser generator tool.
- Very widely used for the processing of computer languages
- more than other kinds of generated parsers.
- LR is an acronym:
- L
- means that the parser reads input text in one direction without backing up
- typically from Left to right within each line, and top to bottom across the lines of the full input file.
- This is true for most parsers
- That's why linear parsing time is guaranteed.
- R
- means that the parser produces a reversed Rightmost derivation
- It does a bottom-up parse,
- not a top-down LL parse or ad-hoc parse
- LR(k)
- Often followed by a numeric qualifier
- as
- LR(1)
- or sometimes LR(k)
- To avoid backtracking or guessing
- The LR parser is allowed to peek ahead at "k" lookahead input symbols
- before deciding how to parse earlier symbols.
- Typically "k" is 1 and is not mentioned.
- LR parsers are deterministic
- produce a single correct parse without guesswork or backtracking, in linear time.
- Ideal for computer languages
- not suited for human languages
- which need more flexible but slower methods
- By convention
- The LR name stands for the form of parsing invented by Donald Knuth
- and excludes the earlier, less powerful precedence method
- e.g.
- Operator-precedence parser
- LR parsers can handle a larger range of languages and grammars than
- precedence parsers
- or top-down LL parsing
- This is because
- the LR parser waits until it has seen an entire instance of some grammar pattern before committing to what it has found.
- An LL parser has to decide or guess what it is seeing much sooner,
- when it has only seen the leftmost input symbol of that pattern.
- LR is also better at error reporting.
- It detects syntax errors as early in the input stream as possible.
- A * 2 + 1
- Scans and parses the input text in one forward pass over the text.
- Builds up the parse tree
- incrementally,
- bottom up,
- and left to right,
- without guessing or backtracking.
- Before there is enough input parsed for building a bigger tree or complete tree,
- Nodes built by parsed input will temporarily held in a parse stack.
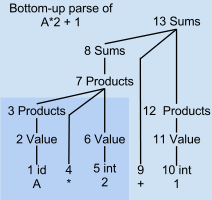
- Shift and reduce actions
- Shift-reduce parsers
- is a class of efficient, table-driven bottom-up parsing methods for computer languages and other notations formally defined by a grammar.
- LR parsing is one of the shift-reduce methods.
- The outward actions of an LR parser are best understood by ignoring the arcane mathematical details of how LR parser tables are generated,
- and instead looking at the parser as just some generic shift-reduce method.
- As with other shift-reduce parsers, an LR parser works by doing some combination of Shift steps and Reduce steps.
- Shift step
- advances in the input stream by one symbol.
- That shift symbol becomes a new single-node parse tree.
- Reduce step
- applies a completed grammar rule to some of the recent parse trees,
- joining them together as one tree with a new root symbol.
- Ex:
- A (shift)
- 1 id (reduce)
- 2 value (reduce)
- 3 Products (reduce) -> ?? not sure I get it.
- * (shift)
- 4 (reduce) -> I think 3 and 4 is misplaced, or 3 should not exist at all (??)
- 2 (shift)
- 5 int (reduce)
- 6 value (reduce)
- A * 2
- 7 Products (reduce)
- +
- 9
- 1
- 10 int
- 11 value
- A * 2 + 1
- 13 Sums (reduce)
- Complete!!
- LR parsers differ from other shift-reduce parsers in how they decide when to reduce
- and how to pick between rules with similar endings.
- But the final decisions and the sequence of shift or reduce steps are the same.
- Much of the LR parser's efficiency is from being deterministic.
- To avoid guessing, the LR parser often looks ahead (rightwards) at the next scanned symbol, before deciding what to do with previously scanned symbols.
- the lexical scanner works one or more symbols ahead of the parser.
- The lookahead symbols are the 'right-hand context' for the parsing decision.
- Bottom-up parse stack
- LR parser lazily waits until it has scanned and parsed all parts of some construct before committing to what the combined construct is.
- Like other shift-reduce parsers.
- The parser then acts immediately on the combination instead of waiting any further.
- Ex.
- the phase A gets reduced to Values and then to Products in steps 1-3 as soon as lookahead * is seen.
- !!!!!! answered my question very well!!
- Rather than waiting any later to organize those parts of the parse tree.
- The decisions for how to handle A are based only what the parser and scanner have already seen, without considering things that appear much later to the right.
- Reductions reorganize the most recently parsed things,
- immediately to the left of the lookahead symbol. --> Not sure I get it.
- So the list of already-parsed things acts like a stack.
- This parse stack grows rightwards.
- The base or bottom of the stack is on the left and holds the left most.
5.3.15
LL parser
- is a top-down parser
- for subset of context-free languages.
- It parses the input from Left to right
- performing Leftmost derivation of the sentence.
- LL(k) grammar
- An LL parser is called an LL(k) parser
- if it uses k tokens of lookahead when parsing a sentence.
- If such a parser exists for a certain grammar and it can parse sentences of this grammar without backtracking then it is called an LL(k) grammar.
- LL parsers can only parse languages that have
- LL(k) grammars without ε-rules.
- LL(k) grammars without ε-rules can generate more languages the higher the number k of lookahead tokens.
- LL(*) parser
- An LL-regular parser.
- if it is not restricted to a finite k tokens of lookahead,
- but can make parsing decisions by recognizing whether the following tokens belong to a regular language
- e.g.
- by means of Deterministic Finite Automaton.
LALR文法分析器
- 是LR的一种简化形式:
- 需要更小的内存空间
- LR需要的分析表需要一个巨大的内存空间
- 通常指
- LALR(1)分析器
- LALR分析方法基于LR(0)分析法演化而来
- 相比较与其他LR分析器
- LALR分析器在一次简单的对输入流进行从左到右扫描时
- 可以更直接的根据向前看的“那个字符”确定一个
- 从下至上的分析方法(How???)
- 这些是归功于LALR分析器不需要回溯
- J:所有LR都不需要回溯啊??!!
- 关于实现
- 由于LALR分析器采用了最右推导而不是最左推导
- 理解LALR分析器的工作方法变得十分困难(??)
- 这导致了手动构造一个LALR分析器是一个消耗巨大而费时的工作。
- yacc/Bison -> LALR
- ANTLR -> LL(*)
3.3.15
Subscribe to:
Posts (Atom)