- Enterprise Integration Patterns - Aggregator
- TechiQuest by Matt Vickery: Spring Integration - Splitter-Aggregator
- Spring Integration - Robust Splitter Aggregator | Javalobby
- spring-integration-samples/intermediate/splitter-aggregator-reaper at master · SpringSource/spring-integration-samples · GitHub
- Spring Integration - Splitter-Aggregator | Javalobby
- java - Configuring a Spring Integration aggregator to combine responses from a RabbitMq fanout exchange - Stack Overflow
- Setup Aggregator in Spring Integration 2 | Develop and Conquer
- 2. Spring Integration Overview
- 5. Message Routing
Aggregator in EIP
- A Splitter is useful to break out a single message into a sequence of sub-messages that can be processed individually. Likewise, a Recipient List or a Publish-Subscribe Channel is useful to forward a request message to multiple recipients in parallel in order to get multiple responses to choose from. In most of these scenarios, the further processing depends on successful processing of the sub-messages. For example, we want to select the best bid from a number of vendor responses or we want to bill the client for an order after all items have been pulled from the warehouse.
This is the context. Splitter is the opposite pattern to Aggregator.
I could understand "to get multiple response to choose from". But I don't understand the concept of "sub-message".
- How do we combine the results of individual, but related messages so that they can be processed as a whole?
But? Oh yeah.
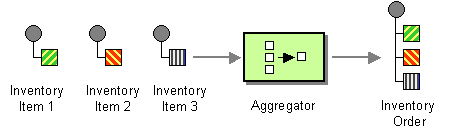
- Use a stateful filter, an Aggregator, to collect and store individual messages until a complete set of related messages has been received. Then, the Aggregator publishes a single message distilled from the individual messages.
- The Aggregator is a special Filter that receives a stream of messages and identifies messages that are correlated. Once a complete set of messages has been received (more on how to decide when a set is 'complete' below), the Aggregator collects information from each correlated message and publishes a single, aggregated message to the output channel for further processing.
Self-starting Aggregator
- When an Aggregator receives a message that cannot be associate to an existing aggregate, it will create a new aggregate. Therefore, the Aggregator does not need prior knowledge of the aggregates that is may produce. Accordingly, we call this variant a Self-starting Aggregator.
- The Aggregator may have to deal with the situation that an incoming message belongs to an aggregate that has already been closed out, i.e. after the aggregate message has been published. In order to avoid starting a new aggregate, the Aggregator needs to keep a list of aggregates that have been closed out.
- We (also) need to provide a mechanism to purge this list periodically so that it does not grow indefinitely.
- This assumes that we can make some basic assumptions about the time frame in which related messages will arrive.
Control Bus
- Allowing the Aggregator to listen on a specific control channel which allows the manual purging of all active aggregates or a specific one.
- This feature can be useful if we want to recover from an error condition without having to restart the Aggregator component.
- Alowing the Aggregator to publish a list of active aggregates to a special channel upon request can be a very useful debugging feature.
- Both functions are excellent examples of the kind of features typically incorporated into a Control Bus.
Initialized Aggregator
Recipient List
Composed Message Processor
Scatter-Gather
Aggregator in Spring Integration
I just realized that I don't know how to use Aggregator.
How Does Splitter-Aggregator Work?
This article confused me. It seems that <aggregator/> doesn't need any parameter and it works! Let this be my start point.
I created a very simple integration workflow like this:
<int:channel id="input"/>
<int:chain input-channel="input">
<int:splitter expression="payload.split(',')"/>
<int:aggregator/>
<int-stream:stdout-channel-adapter append-newline="true"/>
</int:chain>
Within the test program:
input.send(MessageBuilder.withPayload("1,2,3,4").build);
And it works!
So I printed out the messages:
These were the messages after being splitted:
[Payload=1][Headers={timestamp=1369799663894, id=720bb91e-a570-42f2-b088-59acc563e284, correlationId=612a3c7c-6cc4-4d60-bb91-d007200fad4f, sequenceSize=4, sequenceNumber=1}]
[Payload=2][Headers={timestamp=1369799663896, id=b6d33028-8e40-46a7-8421-62f57cf13967, correlationId=612a3c7c-6cc4-4d60-bb91-d007200fad4f, sequenceSize=4, sequenceNumber=2}]
[Payload=3][Headers={timestamp=1369799663896, id=e91ffbe6-cb43-4191-8cea-cbb7a18053c6, correlationId=612a3c7c-6cc4-4d60-bb91-d007200fad4f, sequenceSize=4, sequenceNumber=3}]
[Payload=4][Headers={timestamp=1369799663896, id=e8001450-547a-41aa-9dd4-ae474196c011, correlationId=612a3c7c-6cc4-4d60-bb91-d007200fad4f, sequenceSize=4, sequenceNumber=4}]
And these was the message after being aggregated:
[Payload=[1, 2, 3, 4]][Headers={timestamp=1369799663897, id=c4a661ad-c32d-47e5-9cfe-2e6dcf2c4dc1, correlationId=612a3c7c-6cc4-4d60-bb91-d007200fad4f}]
- correlationId
- sequenceSize
- sequenceNumber
The API for performing splitting consists of one base class, AbstractMessageSplitter, which is a MessageHandler implementation, encapsulating features which are common to splitters, such as filling in the appropriate message headers CORRELATION_ID, SEQUENCE_SIZE, and SEQUENCE_NUMBER on the messages that are produced. This enables tracking down the messages and the results of their processing (in a typical scenario, these headers would be copied over to the messages that are produced by the various transforming endpoints), and use them, for example, in a Composed Message Processor scenario.
The Aggregator combines a group of related messages, by correlating and storing them, until the group is deemed complete. At that point, the Aggregator will create a single message by processing the whole group, and will send the aggregated message as output.
Implementing an Aggregator requires providing the logic to perform the aggregation (i.e., the creation of a single message from many). Two related concepts are correlation and release.
Correlation determines how messages are grouped for aggregation. In Spring Integration correlation is done by default based on the MessageHeaders.CORRELATION_ID message header. Messages with the same MessageHeaders.CORRELATION_ID will be grouped together. However, the correlation strategy may be customized to allow other ways of specifying how the messages should be grouped together by implementing a CorrelationStrategy (see below).
To determine the point at which a group of messages is ready to be processed, a ReleaseStrategy is consulted. The default release strategy for the Aggregator will release a group when all messages included in a sequence are present, based on the MessageHeaders.SEQUENCE_SIZE header. This default strategy may be overridden by providing a reference to a custom ReleaseStrategy implementation.
It is not difficult to write a very simple program to just generate messages for Aggregator's default behavior:
int maxNum = 100;
for(int m=0; m<10; ++m) {
for (int k = 0; k < maxNum; ++k) {
input.send(MessageBuilder.withPayload(String.valueOf(m + k))
.setCorrelationId(String.valueOf(m))
.setSequenceNumber(m * 100 + k).setSequenceSize(maxNum)
.build());
}
}
But what if I need to handle some more complex situation? How could I use ReleaseStrategy and CorrelationStrategy?

- The AggregatingMessageHandler (subclass of AbstractCorrelatingMessageHandler) is a MessageHandler implementation, encapsulating the common functionalities of an Aggregator (and other correlating use cases)
- correlating messages into a group to be aggregated
- maintaining those messages in a MessageStore until the group can be released
- deciding when the group can be released
- aggregating the released group into a single message
- recognizing and responding to an expired group

I can find all corresponding implementation for the first 4 functionalities, but the 5th one. One thing that confused me here: ! (!messageGroup.isComplete() && messageGroup.canAdd(message)).
!(!messageGroup.isComplete() && messageGroup.canAdd(message))
==> messageGroup.isComplete() || !messageGroup.canAdd(message)
What does messageGroup.isComplete() mean?
- True if the group is complete (i.e. no more messages are expected to added)
This makes sense to me now. So if the message group is not expecting to add any new messages, then the new message will be sent to the discardChannel.
But wait, is a complete message group an expired group? How do they define an Expired Group? That was something bothered me a lot in my previous testing.
Here are some related information:
- Setting expire-groups-upon-completion to true (default is false) removes the entire group and any new messages, with the same correlation id as the removed group, will form a new group.
- Partial sequences can be released by using a MessageGroupStoreReaper together with send-partial-result-on-expiry being set to true.
For the first one, here is the implementation:

For the second one:

and expireGroup(correlationKey, group) is called by forceComplete(group).
From what I can see here, I think an expired group is a group that is removed from the messageStore:
The 5th functionality is "
- recognizing and responding to an expired group
". There are three places that an expired group is recognized:
- expire-groups-upon-completion. If this option is set, a message group will be removed when it is completed. It is easy to see whether a message group is complete, using MessageGroup.isComplete(). However, the following code confused me:

Please take a look at handleMessageInternal(xxx)
When releaseStrategy.canRelease(messageGroup) is true, a message group will be set as complete. But complete means that other message targeting to the same message group, or in another word, with the same correlationKey, will be discarded. Really? Can I find any documentation for this?
- When the group is released for aggregation, all its not-yet-released messages are processed and removed from the group. If the group is also complete (i.e. if all messages from a sequence have arrived or if there is no sequence defined), then the group is marked as complete. Any new messages for this group will be sent to the discard channel (if defined).
- Setting expire-groups-upon-completion to true (default is false) removes the entire group and any new messages, with the same correlation id as the removed group, will form a new group.
Here it is!! But I am still confused about "if the group is also complete". I didn't see these if from AggregatingMessageHandler.
And I think this is why my simple test didn't work. Because I am trying to use the same correlation key, which is a string literal. When release strategy is satisfied, the group is complete and not expecting any other messages. All message after that will be discarded and I didn't provide a discard channel.
However, if "expire-groups-upon-completion", message group will be removed, which is so called expired. When there is new message arrive, a new group with the same correlation key will be created and begin to accept message again.
MessageGroupProcessor
The Aggregation API consists of a number of classes. And the first one is:
- The interface MessageGroupProcessor, and its subclasses: MethodInvokingAggregatingMessageGroupProcessor and ExpressionEvaluatingMessageGroupProcessor


It looks like a Bridge Pattern.
- AbstractCorrelatingMessageHandler bridges its message group processing implementation to a MessageGroupProcessor. Then the Message Handler part could focus on handling the messsages. It has two variants: AggregatingMessageHandler, and ResequencingMessageHandler.
- For MessageGroupProcessor, there are three major categories of it.
Of course, you can call it a Strategy Pattern, because MessageGroupProcessor is the MessageHandler's strategy for handling MessageGroup.
Anyway, I am interested in its name: outputProcessor. Why?

This is the only place that outputProcessor is used. That means, MessageGroup is only used when the Aggregator tries to complete the group, or tries to send out the message, and outputProcessor helps the Aggregator to process the messages, and generate the result(s).
Then outputProcessor makes sense.
One thing need to note here is that the result will be sent out at line 379. I don't know why they have partialSequence here and why they return it back, but it seems that nobody use this return value the the subsequent call.
AbstractAggregatingMessageGroupProcessor
- Here is a brief highlight of the base AbstractAggregatingMessageGroupProcessor (the responsibility of implementing the aggregatePayloads method is left to the developer)
- aggregateHeaders(MessageGroup group)
- aggregatePayloads(MessageGroup group, Map<String, Object> defaultHeaders)

This is a typical Template Method solution. Since we usually don't want to change the aggregateHeaders() part, it is worthy to take a look at the default implementation:

- In a word, it removes all the non-consistent headers
- ID
- TIMESTAMP
- SEQUENCE_NUMBER
- conflict header
- But it also remove SEQUENCE_SIZE. I think it is because they believe SEQUENCE_SIZE is one only for Aggregator.
No comments:
Post a Comment